Мозковий імплант надав можливість пацієнту з БАС спілкуватися власним голосом.
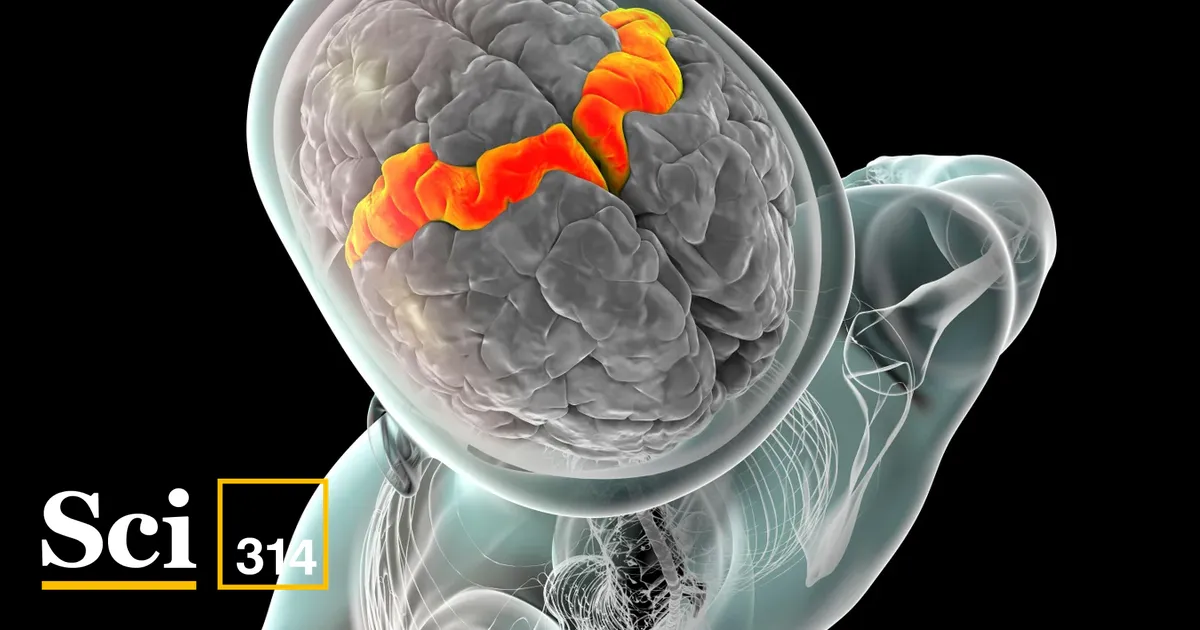
Американські дослідники розробили апарат, здатний переводити мозкові сигнали на мову, наділену емоціями та інтонаціями, в режимі реального часу.
Кейсі Харелл протягом багатьох років був активним захисником клімату, виступаючи на різноманітних публічних заходах і політичних форумах. Однак його життя змінилося, коли він втратив можливість говорити через бічний аміотрофічний склероз. Це захворювання значно ослабило м'язи його рота та горла, унаслідок чого він більше не міг виразно висловлювати свої думки. Нині, завдяки мозковому імпланту, Кейсі знову має можливість говорити своїм голосом, передаючи емоції та інтонації в реальному часі.
Прилад, який випробовували науковці з Каліфорнійського університету в Девісі, має можливість миттєво перетворювати мозкові сигнали на мовлення. Це частина розвиваючої галузі, яка отримала назву інтерфейси мозок-комп'ютер. Однак цей пристрій вирізняється своєю здатністю відтворювати природний ритм мови — він здатен передавати не лише слова, а й тональність, акценти та паузи, що надають мовленню людяності.
Система, представлена цього тижня в журналі Nature, застосовує штучний інтелект для перетворення рухових сигналів мозку в мовлення. Її швидкість достатня для ведення діалогу, а також вона здатна допомагати користувачам виконувати короткі пісенні фрагменти. Це становить важливий прогрес для тих, хто втратив можливість виразно спілкуватися.
Харелл, якому нині 47, вперше зіткнувся з діагнозом бічного аміотрофічного склерозу п'ять років тому. Ця нейродегенеративна хвороба повільно знищувала нервові з'єднання, що відповідали за контроль над м'язами губ, язика та горла. Незважаючи на те, що він все ще міг видавати звуки, його мова стала важкозрозумілою.
У попередньому дослідженні команда під керівництвом Харелла імплантувала масив з 256 електродів у ту частину мозку, що відповідає за рух. Ці мікроскопічні кремнієві сенсори, довжина яких становить всього 1,5 міліметра, реєстрували електричну активність тисяч нейронів. У новій роботі науковці інтегрували отримані дані з моделлю глибокого навчання, яка перетворювала мозкові сигнали на зрозумілі слова з швидкістю, практично ідентичною природному мовленню.
Синтетичний голос не обмежується заздалегідь заданими словами або фразами. Він здатний розпізнавати звуки, в тому числі вигуки на кшталт «хм» або незрозумілі слова, які алгоритм раніше не зустрічав. Крім того, він може варіювати інтонацію в середині речення.
"Ми включаємо всі ці різні елементи людського мовлення, які дійсно важливі", -- сказала провідна дослідниця Майтрейі Вайрагкар. "Ми не завжди використовуємо слова, щоб передати те, що хочемо".
Ця тонка деталь є надзвичайно важливою. В одному з експериментів Харелл застосував систему, щоб озвучити речення як ствердження та запит. Програмне забезпечення автоматично регулювало висоту тону. У іншому випадку він виконав серію музичних нот у трьох різних тонах. Те, що прозвучало з динаміка, безсумнівно, було його голосом, відтвореним з записів, зроблених до того, як БАС забрала його.
Більшість попередніх мовленнєвих інтерфейсів мозок-комп'ютер працювали ривками. Вони могли перекладати лише повні речення після того, як людина закінчувала імітувати всю фразу. Деякі потребували до трьох секунд для відповіді, що занадто повільно для розмови.
"Вам не дозволяється переривати співрозмовників, не можна заперечувати їхні слова чи співати", -- зазначив Сергій Ставіський, нейробіолог з Каліфорнійського університету в Девісі та один з авторів дослідження, розповідаючи про попередні пристрої. "Це кардинально змінює ситуацію". Нова система реагує всього за 25 мілісекунд — приблизно стільки ж часу, скільки потрібно, щоб голос людини дійшов до її власних вух.
Волонтери, які слухали синтетичний голос Харелла, змогли зрозуміти 60% його слів, у той час як без підтримки їхнє розуміння знижувалося до всього 4%. Це, звісно, ще не ідеально. Його текстовий інтерфейс мозок-комп'ютер, що базується на великих мовних моделях для аналізу кожного висловлювання після його озвучення, демонструє набагато вищу точність — близько 98%. Однак він також працює повільніше і є менш гнучким.
"Це справжній святий Грааль у сфері мовленнєвих інтерфейсів мозок-комп'ютер," — зазначив Крістіан Герфф, обчислювальний нейробіолог з Маастрихтського університету, у коментарі для Scientific American. "Тепер ми маємо справу з реальним, спонтанним і безперервним мовленням."
Мабуть, найбільш захоплюючим аспектом є те, що система здійснює декодування не на основі фонем або словникових записів, а безпосередньо з акустичних хвиль. Це створює можливості для багато мовної підтримки — потенційно навіть для тональних мов, таких як китайська, а також для збереження індивідуальних акцентів.
Успіх цього дослідження супроводжується певними застереженнями. БАС Харелла ще не призвів до деградації рухового кортексу до нефункціонального стану. Залишається дізнатися, чи зможе та ж сама система працювати у пацієнтів з іншими неврологічними ураженнями, наприклад, після інсульту.
Саме це дослідники планують з'ясувати далі. Нове клінічне випробування під керівництвом Девіда Брандмана з Каліфорнійського університету в Девісі тестуватиме імпланти з ще більшою кількістю електродів -- до 1600 -- у людей із різними порушеннями мовлення.
Мета, на думку Вайрагкара, полягає не лише в відновленні голосу. Це процес відновлення цілого спектру людського досвіду спілкування: спонтанності, емоційності та ідентичності.
"Це певною мірою зміна уявлень", -- зауважила Сільвія Маркесотті, нейроінженерка з Женевського університету. "Це дійсно може стати основою для розробки практичного інструмента".
Для Харелла це вже виступає в ролі певного інструменту.
Інші публікації





Популярне


У тренді









